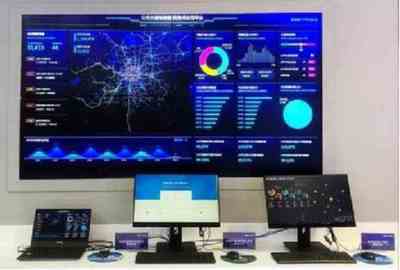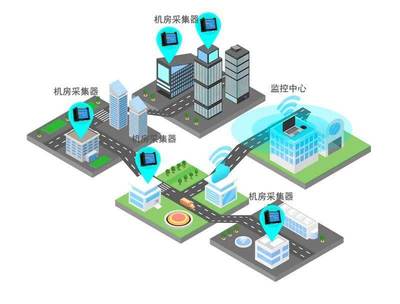
随着企业微服务架构的普及和大数据服务的广泛应用,构建一个可伸缩、高效的微服务告警系统对于保障系统稳定性和数据可靠性至关重要。本文将介绍一个针对大数据服务的可伸缩微服务告警系统设计指南,涵盖核心原则、关键组件和最佳实践。
一、核心设计原则
- 可伸缩性:系统应能够在负载增加时动态扩展,以应对大数据服务中可能出现的海量告警事件。建议采用分布式架构,并利用容器化技术(如Docker和Kubernetes)实现弹性伸缩。
- 实时性:大数据服务通常涉及实时数据处理,告警系统需要低延迟地检测和通知异常。集成流处理框架(如Apache Kafka或Flink)以支持实时告警生成。
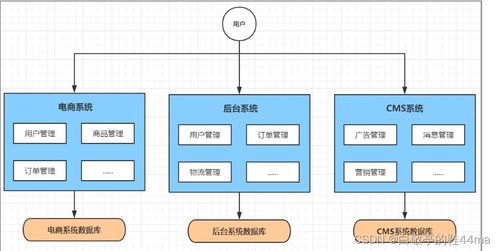
- 模块化与解耦:将告警系统拆分为多个独立微服务,例如数据收集、规则引擎、通知服务等,便于独立扩展和维护。使用消息队列(如RabbitMQ或Redis)实现服务间异步通信。
- 容错与高可用:通过冗余部署、健康检查和自动故障转移机制确保系统在部分组件失效时仍能正常运行。
二、关键组件设计
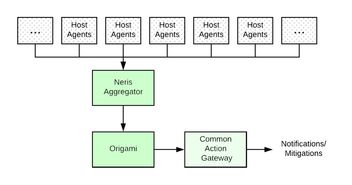
- 数据收集层:负责从大数据服务(如Hadoop、Spark或实时数据管道)收集指标和日志。可部署轻量级代理(如Prometheus exporters或Fluentd)以非侵入式方式采集数据,并支持多种数据源。
- 规则引擎层:处理收集到的数据,根据预定义规则(如阈值、异常模式)触发告警。采用可配置的规则引擎(如Drools或自定义DSL),并支持动态规则更新,以适应大数据服务的多变场景。
- 告警处理与聚合层:对告警进行去重、聚合和优先级排序,避免告警风暴。实现智能聚合算法,例如基于时间窗口或拓扑关系的分组。
- 通知与行动层:通过多渠道(如邮件、短信、Slack或Webhook)发送告警,并集成自动化脚本以执行修复操作(如重启服务或缩放资源)。
- 监控与反馈循环:系统自身应被监控,收集性能指标,并通过机器学习模型(可选)优化告警规则,减少误报和漏报。
三、可伸缩性实现策略
- 水平扩展:使用负载均衡器分发数据收集和规则处理任务到多个实例。
- 数据分区:对大数据服务的告警数据按服务、区域或时间进行分区,提高并行处理能力。
- 资源优化:结合云原生技术(如自动伸缩组)根据CPU、内存或队列长度动态调整资源。
四、针对大数据服务的特殊考虑
- 处理海量数据:告警系统应与大数据平台(如Elasticsearch或ClickHouse)集成,以高效存储和查询历史告警数据。
- 实时流处理:在规则引擎中集成复杂事件处理(CEP)功能,以检测大数据流中的异常模式。
- 成本控制:通过采样或智能过滤减少不必要的数据处理,降低云资源成本。
五、最佳实践与部署建议
- 逐步部署:先在非关键服务上测试告警系统,再逐步扩展到核心大数据服务。
- 文档与培训:为团队提供清晰的告警策略文档,并定期进行演练。
- 持续改进:基于告警数据分析,定期审查和优化规则,确保系统随业务增长而演进。
一个可伸缩的微服务告警系统对于大数据服务来说,不仅是技术挑战,更是业务连续性的保障。通过遵循模块化设计、实时处理和弹性伸缩原则,企业可以构建一个高效、可靠的告警生态系统。